
Businesses today deal with larger, more complex data sets than at any point in history. Obviously, this brings huge benefits. At the same time, it introduces swathes of new challenges.
These include inefficiencies, unnecessary risks, poor oversight, and a whole host of other problems.
One approach to solving this problem is simplifying data management. See, the problem isn’t so much the data itself, it’s how we build processes and operations around it.
The thing most businesses get wrong is failing to adequately match their data management processes to their real-world business requirements - in terms of how they use or analyze data across its entire life cycle.
Today, we’re diving deep into everything that you need to know about creating simplified, effective data management processes.
We’ll start by examining the role of data management in day-to-day operations, alongside some of the key challenges that this presents. We’ll also think about some of the key impetuses for simplification and optimization.
Then, we’ll move on to our specific tips for implementing simplified data management, as well as a step-by-step framework that you can use to achieve this.
Let’s start with a bit of background.
What is data management?
This might seem like a simple question, but it bares drilling into. Data management is the sum of all of your efforts to gather, store, share, organize, analyze, gain insights, and leverage data assets across your organization - as well as how we keep data secure without impacting operational efficiency.
We're also dealing with infrastructure management, data governance, and managing and maintaining cloud platforms.
That’s a pretty big mandate.
So, let’s put it another way. Data management comprises a whole host of tools, technologies, and strategies for helping us use our data assets to facilitate business processes.
What this actually looks like in practice will vary hugely from one organization to the next.
A big factor here is obviously the scale of your internal data assets. For example, in many smaller companies, this could basically start and end with your customer database.
In these cases, our data management would mostly surround enabling individual users to interact with this data in a controlled manner - whether this is for the purpose of aggregation and analysis - or simply performing administrative.
In larger organizations, the picture is typically a lot more complex. What we’ll often see here is multiple distinct levels of individual data management activities. Within individual departments, we might see the kinds of data management that we just discussed in smaller organizations.
As in, your logistics team, will need to manipulate and use data relevant to their patch - like inventory, supply chain, or manufacturing databases.
On top of this, we’ll also have additional layers of data management - largely though not exclusively across operations, IT, and senior leadership teams.
One important element of this is managing how data moves across your organization. For instance, ETL processes, data centralization, infrastructure and hosting tasks, security, access control, and more.
You might also like our round-up of the top Airtable alternatives.

(EdQ)
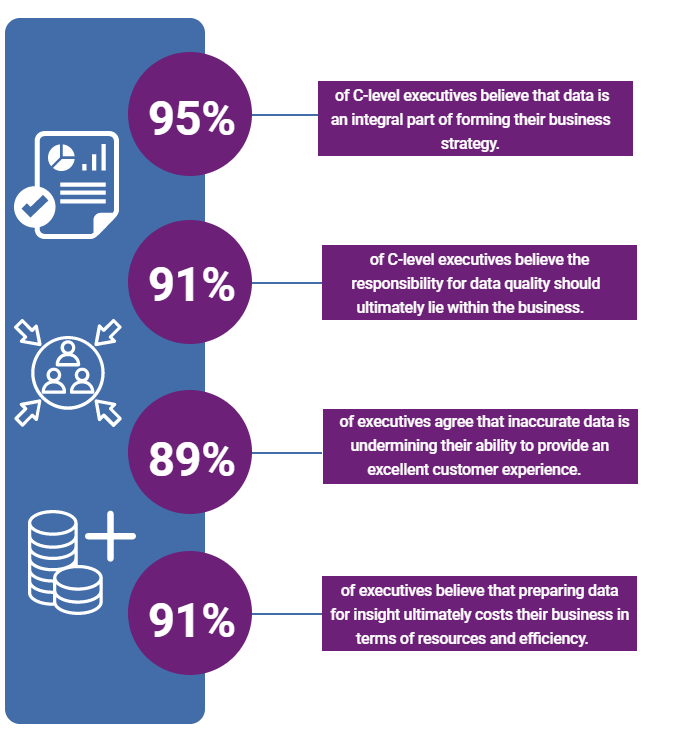{kind=link}
Besides this, we have what’s known as our enterprise data model. This comprises all of our organizational data, how assets relate to each other, how each is used, and what it all means.
But, now we’re getting into specific strategies. Before we check out our tips for simplified data management, let’s take a step back and think about why all of this matters.
Data management challenges
We know that data is a modern business’s most valuable asset. The core challenge is actually extracting this value by putting our data to use. We can break this down into a few different issues that we need to account for in our data management efforts.
The first issue is actually acquiring the data we need. In some cases, we might be literally dealing with sourcing data - but for the most part, the task here is collating existing data sources.
We may have multiple potential sources of the same information - even if this is something internal, like our conversion rate. The goal is to have a single, reliable source of truth for every constituent metric in our data model.
For many, the next step after this is centralization. One of the most common challenges that businesses face is siloed data. That is, when each team or department has its own data assets, without knowing what’s going on elsewhere in the business.
Modernizing data management processes using central resources like data warehouses or data lakes is the most effective solution to this problem.
Then, there’s the challenge of getting the right data in front of the right people - while also maintaining security and appropriate exposure to different data assets for specific users.
Effectively, this is a question of what data users can access, what they can do with it, and how.
On top of this, we have a whole host of related challenges in terms of ensuring reliability, uptime, accuracy, validity, efficiency, and other key metrics - both at the level of individual processes and our data management efforts as a whole.

(McKinsey)
Why simplify data operations?
Clearly, data management is a far-reaching, diverse set of interrelated processes, transformations, and other activities.
When we talk about simplifying this, we’re actually talking about taking a more targeted approach to managing data that closely mimics the requirements of real-world business processes.
The goals are reinforcing efficiency, repeatability, and visibility across our data management efforts - while also seeking to facilitate automation and remove unnecessary or extraneous manual admin tasks.
In a way, simplification is a bit of a misnomer. The key thing is creating an environment where we can achieve the most value in our day-to-day data management tasks with the least possible human intervention and maximum efficiency.
10 strategies for simplified data management
With that in mind, let’s check out the specific interventions that are going to have the biggest impact. Since data management is such a diverse suite of activities, we’ve broken this down into a few key categories.
Let’s dive right in.
Data administration
Data administration largely means the kinds of tasks that involve performing basic operations on individual entities or objects within a database. So things like creating, reading, updating, and deleting records.
This takes up huge swathes of users’ time within a diverse range of processes, so let’s check out some of our options for alleviating this administrative burden.
1. Data entry automation
First, we have data entry automation. This is a relatively simple way to achieve big efficiency savings - since data entry is such a ubiquitous task in all sorts of processes. Large companies even have dedicated data entry teams.
There are several approaches that we can take to eliminate the need for manual data entry through automation. One is prioritizing integration between platforms. For instance, API-based solutions that move data between individual platforms, reducing the need for data entry.
Another option is a more wholesale move towards large-scale automated data pipelines, as we’ll see in a second. We’ve also created an in-depth guide to data entry automation.

2. Internal tools and process applications
Besides automation, we also need to account for the ways users interact with data where manual admin tasks are retained. The goal here is to provide experiences that efficiently guide users through carrying out defined tasks.
One of the best options here is providing dedicated internal tools or process applications for specific tasks and workflows.
Typically, this means providing lightweight, intuitive interfaces for carrying out very specific admin actions on subsets of data, as required by particular internal processes.
To learn more, check out our ultimate guide to custom app development.
Analytics, visualization, and monitoring
Next, we have strategies related to how we prepare and use data for analytics and visualization. The challenging thing here isn’t so much the actual calculations and aggregation we need to apply.
Rather, it’s the work that precedes this in terms of preparing data to be usable for extracting insights.
Here are some of the most important strategies in this area.
3. Data lakes, warehousing, and centralization
Centralization means creating a unified, accessible, and authoritative store for all of your organizational data. Users and processes can then leverage and manage otherwise distinct data in a convenient, coherent fashion.
The two main approaches here are data lakes and data warehouses. A data lake is a large repository of different kinds of data - all stored in their original format. This provides a valuable resource, as we can apply any kind of transformations and aggregation we need for analysis.
A data warehouse differs from a data lake in the sense that it is stored in a format and structure that’s defined for a specific purpose. This is useful if we need to carry out similar analytical operations on a large scale.
4. Enterprise data modeling
As we said earlier, an enterprise data model is a detailed account of all of the data assets that are involved in core business processes - along with where each of these is sourced from, what they’re used for, and how they relate to each other.
This is effectively a data-centric representation of how your business works.
In turn, an effective data model brings along several important benefits. Perhaps chief among these is helping to identify opportunities for integration and other important data ops improvements across the organization as a whole.
Data operations
Next, let’s think a little bit more deeply about data ops. This is a type of data management that’s primarily concerned with how we facilitate the flow of information between different nodes and actors within a business.
5. Establish key data pipelines
Data pipelines are regularized, automated flows of data. More specifically, this is when raw data is taken from its source, before being processed or transformed in some way, and stored in a separate location.
For example, moving sales data from our CRM to a data warehouse - or from a data lake to our analytics platform.
By establishing effective data pipelines, we achieve the dual effects of reducing the need for manual administration and helping to facilitate all sorts of other automation and data-driven transformations.
6. Tracking data lineage
Tracking data lineage is all about establishing visibility and accountability over how our data assets are used and managed in the field.
For example, in the case of a database, the lineage might include who the original creator was, which columns have been added since then, and any merge actions that have taken place.
We can also track the data lineage of individual entities in order to track how and when individual values have been changed - although we’re constrained by what’s possible within specific DBMS platforms.
Infrastructure and storage
Our infrastructure, hosting, and storage solutions also have a huge impact on the outcomes of our data management efforts.
Here are a couple of the most important trends in this domain.
7. Exploring modern database management tools
In the past decade, the landscape of data storage solutions has changed dramatically. It’s not so long ago that almost all business data was stored in SQL-derived solutions, like MySQL, SQL Server, and Postgres.
More recently though, a whole range of object storage, wide-column, and other NoSQL tools have exploded in popularity - especially in the context of big data, machine learning, and AI.
To learn more, check out our guide to relational vs non-relational databases.

(DnB)
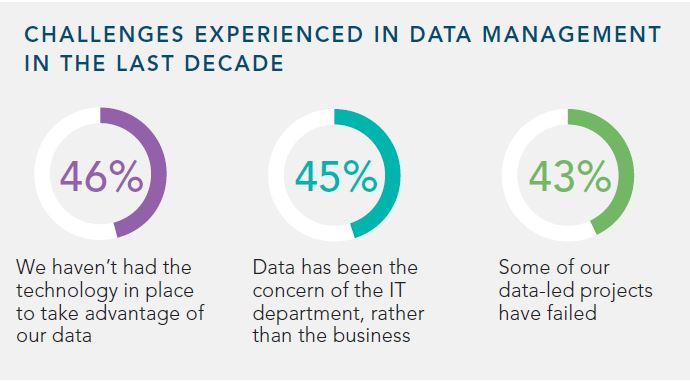{kind=link}
8. Cloud hosting
Cloud-based data storage isn’t exactly a trend anymore. Rather, it’s well and truly in the mainstream. From an ops point of view, one benefit to this is that we can access storage on an as-a-service model - so we only pay for what we need.
This makes our data infrastructure significantly easier to scale, as we don’t need to invest in new hardware as our needs evolve.
Similarly, migrating data management solutions to the cloud has the potential to greatly enhance efficiency, performance, reliability, security, and more.
Governance and control
Finally, we have more policy-driven aspects of how we manage our data. For the most part, this is about ensuring high levels of security and process adherence in our users’ day-to-day interactions with internal data assets.
Here are some of the strategies we can turn to here.
9. Role-based access control
Role-based access control is an approach to administering permissions where we cluster users into defined groups based on their responsibilities within a particular process. Each of these roles is then granted access to the data assets and actions that they need.
This is a very effective way to restrict data exposure on a needs-based basis, without creating excessive administrative work for IT teams or database managers.
Check out our guide to data access control to learn more.
10. Implementing single sign-on
Last, but not least, we have implementing SSO across data management tools. The contextual challenge here is that teams interact with a greater volume of discrete internal tools than ever before.
Efficiently administering authentication and authorization without compromising on security is therefore critical. Using single sign-on, based on standards like OAuth, OpenID, or Microsoft SSO is one of the most effective solutions to this problem.
Users can securely use the same credentials across multiple related applications, providing efficient, secure access.
How to optimize data management processes in 7 steps
Next, let’s think about how we can pull together everything that we’ve learned so far into a repeatable framework for building optimized, simplified data management solutions.
We’ve seen already that we can attack this problem at several distinct levels. This ranges from highly abstract planning and governance around our data and organization-wide interventions, to highly granular optimization in terms of specific user interactions.
Here are the specific steps you can follow to streamline your data management efforts:
- Audit stored data assets - Creating an inventory of the data assets that we currently store and handle - as well as those that we need but lack currently.
- Create an organizational data model - Outlining the roles, sources, and relationships of different data assets.
- Centralization - Exploring opportunities for leveraging centralization in the form of data lakes or warehouses.
- Data flows and pipelines - Establishing the regular flows of data that are required as part of your core business processes.
- Automations - Identifying opportunities to eliminate manual data management actions through automations.
- Facilitating user interactions - Strategizing around how to implement remaining user interactions in the most effective way possible.
- Monitoring and ongoing optimization - Monitoring the success of our transformation efforts and ideating on new areas for improvement.
Join 300,000 teams running operations on Budibase
Get started for freeTurn data into action
At Budibase, we’re on a mission to empower teams to turn data into action. Our open-source, low-code platform offers market-leading external data support, auto-generated UIs, role-based access control, optional self-hosting, extensive customization, and more.
To learn more about using Budibase to simplify your data management processes, take a look at our features overview.