
Data is the foundation of every successful organization today. Therefore, it follows that your choice of data management solutions has an outsized impact on the wider business. This is a lot of pressure for IT teams to get things right.
The trouble is that data management is a pretty broad field, to say the least. Your decision-making here is going to affect just about every process at every level of your business - but, even worse, the effect won’t be uniform.
Today, we’re diving deep into everything you need to know about providing effective data management solutions across your business - from streamlining IT ops to empowering departmental leaders with the insights they need to make better decisions in the field.
Of course, we’ll also look at some more specific examples, use cases, challenges, and our top-pick platforms along the way.
That’s a lot to cover, so settle in.
But, before we get to all of that, it’s worth starting with the basics.
What is data management?
Data management comprises all of your efforts to collect, store, organize, and use data across your entire organization. The goal is to maximize security, efficiency, and accessibility - while minimizing the costs incurred.
This covers a huge range of overlapping policies, procedures, tasks, and technologies - so it’s worth thinking about some of the high-level themes that your IT team deals with under the umbrella of data management.
This includes (but obviously is not limited to):
- How colleagues interact with data, including creating, reading, updating, and deleting individual entries and aggregated data.
- How and where data is stored.
- How we maintain validity, accuracy, and integrity within datasets.
- The processing, pipelines, and automations used to pool, consolidate, aggregate, and leverage data from disparate sources.
- Integration between different platforms.
- Security, compliance, and regulatory processes.
- Infrastructure monitoring and maintenance.
- Archiving, deletion, and lifecycle management.
- Managing data access, roles, and exposure for different user groups.
- The administrative tasks required to service specific data sets.
As you can see, data management can range from the very granular tools and techniques used to action specific processes to the wider policies and principles that govern your DataOps.
For the moment, the important thing isn’t to get bogged down in every single possible data management activity.
We’ll come to more specific challenges in good time.
What’s important for now is recognizing the scale, depth, and variety of data management issues that technical teams must contend with.
To understand this better, we can take a further step back.
The role of internal business data
They say that data is a modern business’ most important asset.
But why?
Or, why does every successful company go to such lengths to collect, store, and maintain mountains of internal data?
From a purely business perspective, we’re trying to facilitate two things:
- Informed decision-making.
- Efficient operations.
So, departmental leaders might leverage data to help them decide on the most effective course of action in a given situation. Simultaneously, technical teams use business data to enable the digitalization of particular processes, to make them more cost-effective.
Again, we’re not worried about going into extreme detail on either of these things for the time being.
What’s important for now is understanding the practical implications for the colleagues responsible for facilitating these things.
Namely, your IT and ops teams.
That is, what are the characteristics of data that’s actually useful for informing strategic decisions or streamlining internal operations?
We can point to a few overarching priorities - without getting into the technology that underpins these just yet.
Data management seeks to ensure that data is:
- Accessible - The right people need to be able to access the data they need in a format that’s appropriate to their requirements and level of technical skills.
- Fit-for-purpose - Data must be a relevant, valid operationalization of the business-level issue that it’s trying to measure or represent.
- Scalable - Effective data management seeks to ensure that our data continues to meet our needs in the long term - both in terms of the volume of data we hold and its scope.
- Secure - Security is a top risk factor for modern businesses. Data management solutions are central to these efforts.
- Reliable - We must be able to rely on our data itself, as well as the tools and infrastructure and tools that we use to support this.
- Usable - Data only creates business value when users are actually able to leverage it.
- Performant - Data management ensures that users can access data quickly and that we have the wider technical capability that we need.
- Useful - The data we store must be relevant to our strategic aims.
- Up-to-date - Data is only useful if it is still an accurate reflection of whatever it’s supposed to represent.

(EdQ)
{kind=link}
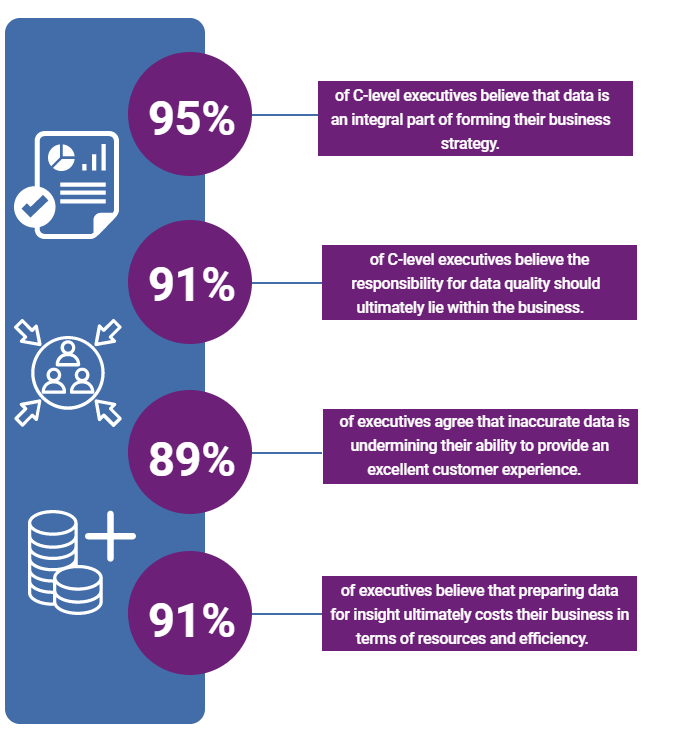
The reality for your business could be very different
If you’re being honest with yourself, how well does your business’ internal data meet these aims?
Probably not as much as you’d like.
The truth is that most of us can talk a good talk when it comes to data management, but in practice, we might still struggle to furnish our users with the insights and tools that they need.
In other words, your data management efforts could more than likely be improved.
Businesses today store and process more data than ever before - that’s indisputable. But, it’s often disorganized, undocumented, and ineffective.
For example, you might have all the data you could ever need - but it’s spread across countless uncoordinated spreadsheets and SaaS platforms within different departments.
More often though, it’ll be more of a mixed picture. So, some of your data assets might be managed perfectly effectively while others are a complete mess.
As we’ll see throughout this article, one of the goals of data management is to bridge this gap.
But first, we can drill a bit more deeply into what data management means in practice.
9 types of data management
We know that data management can mean wildly different things in different contexts. This obviously doesn’t make our lives much easier. So, what we need is an effective taxonomy for the kinds of activities we’ll undertake.
With that in mind, here are the nine core types of data management that we can use in combination with each other as part of our wider strategy.
Data preparation
Data preparation is all about how we clean and transform data so that it’s in the format that we need. Perhaps to make it readable for analytical purposes or to bring disparate data sources into a consistent format so we can combine them.
So, specific actions might include reformatting, aggregating, or validating individual data points. Or, we might equally need to cleanse the wider data set, for instance by removing duplicated, incomplete, or inconsistent entries.
Depending on the size of the data set and your internal resources and skills, data preparation can involve a combination of manual and automated actions. It’s important to prioritize automation so that we don’t sink our ROI with excessive manual processing.

(EdQ)
Data pipelines
The next type of data management is considerably more technical. Data pipelines are automated systems that allow data to be transferred from one system to another.
This might require some of the same individual actions as data preparation - such as reformatting, aggregation, or validation. However, the difference is that data pipelines operate behind the scenes, with no human interaction other than for initial configuration.
Additionally, creating data pipelines generally requires us to use dedicated platforms. We’ll see some of these a little bit later on.
ETLs
ETL stands for extract, transform, load. These are data management systems that take data from one platform, perform any necessary transformations, and load it into the organization’s data warehouse.
Again, ETLs are fairly similar to data pipelines in terms of the nature of the work involved - but they’ll also require their own dedicated data management software solutions.
Basically, the goal here is to ensure that our data, whatever its source, can be added to our centralized resources. More on this in a second.
Data catalogs
Catalogs are a slightly more niche form of data management solution. That is, they’re specifically concerned with how we manage metadata. That is data about our data.
Specifically, data catalogs are used to document how different resources are moved, edited, transformed, stored, and used. The idea is to give a complete picture of a piece of data and its history.
This makes it easier to locate and leverage specific information in large or complex data sets.
Data warehousing
A data warehouse is a centralized location where all your organizational data is consolidated. The idea is to provide a single, accessible route for users across your business to leverage data.
Of course, the challenge here is the scale and variety of the data that your average business sits on today. Obviously, this presents a number of difficulties - both in terms of preparing data for warehousing and maintaining security with effective access controls.
Therefore, the kinds of data management software solutions we need are both highly advanced and specific to individual business requirements.
Data governance
Data governance solutions are an essential - if occasionally underestimated - ingredient of your data management strategy. Essentially, governance is the sum of all of the policies, procedures, and other instruments that we use to control interactions with our data.
Of course, this is a huge field. We have to consider the governance policies themselves, as well as the rationale that underpins them, and - most importantly for our purposes today - the technology we use to enforce them.
This could range from user management tools like RBAC and SSO within your software ecosystem - all the way to advanced, highly automated data management solutions.
Data architecture
Data architecture is all about how your data is structured, as well as the infrastructure that supports your data management efforts. Ultimately, this determines how effectively data flows across your organization.
Architecture also feeds your efforts toward data governance, security, compliance, and accessibility.
Perhaps more so than any of our other categories of data management solutions, architecture is a vast, far-reaching topic in its own right. We’ll look into the important points today, of course, but a comprehensive account is beyond our scope.
Data security
Because data is a modern business’s most important asset, data security is a top risk factor. Therefore, maximizing security is obviously one of the central planks of our data management efforts.
We want to prevent unauthorized access, corruption, leaks, breaches, and other incidents.
We have a range of policy and solution-level levers at our disposal to meet this goal.
Data modeling
Finally, we have data modeling. A data model is a kind of abstract plan of the data our business needs - either for a specific use case or at an organization-wide level. At the most basic level, this includes what we need to know and how we’ll measure it.
Beyond this, data modeling also involves the relationships between different attributes or objects, as well as other information, like relevant access rules or stored procedures.
More specifically to data management solutions, our big concern is maintaining our data model.
What is data management software?
We’ve covered a lot of ground already but it’s been overwhelmingly theoretical. Remember, our focus today is helping you to make an informed decision about the right data management solutions for your specific needs.
Therefore, before we go any further, we’ll obviously need a more detailed understanding of what data management software actually is.
So, let’s start with the most glaringly obvious question.
What does data management software do?
Data management software aims to systematize the way your business collects, stores, organizes, and uses data. We’ve alluded to a lot of what this can mean in practice already when we explored the nine different kinds of data management.
Still, we need to flesh out the more specific technical capabilities that platforms can provide.
The core functionality of most data management solutions is enabling you to integrate and control information - and how it flows across your entire business.
In other words, it acts as a missing link between your raw, uncoordinated data, and the insightful, strategically useful resources that you need.
As we’ll see in a few minutes, different platforms have their own narrower focuses.
But, in general terms, their primary function is offering configurable methods to query, aggregate, compare, combine, and move data across various disparate sources - while also providing users with a secure, reliable way to leverage and interact with this data.
You might deploy this to support your data warehousing, pipelines, ETL, or any other data management efforts.
More specifically, data management solutions provide features around:
- Quality - Ensuring that your data’s validity, integrity, and up-to-dateness.
- Consistency - In terms of values and format.
- Control - Empowering the right people to get actual value from your data.
- Risk - Minimizing security risks and their associated costs.
- Data protection - Maintaining compliance with relevant privacy regulations.
- Administration - Embedding efficiency in relevant admin workflows.
- Automation - Streamlining your data management flows with automated actions.
- Portability - Your ability to move data between different systems and platforms.
- Integration -How easily you can leverage data across different platforms.
Again, we’re going to think about some more concrete use cases and examples in just a few minutes.
Before that though…
Why do we need data management software?
In a sense, you don’t necessarily. At least, the relative importance of data management solutions is directly proportional to the size of your organization and the volume of data that it maintains.
So, if your DataOps only involves a couple of colleagues occasionally sending spreadsheets back and forth, you might not have much to worry about.
More likely though, yours is one of the huge majority of businesses that cite ineffective data management as a top pain point.

(McKinsey)
Why is this?
We don’t have to make such a leap from the core functions that we looked at a second ago to see the value added here. Essentially though, we can point to a few very broad, business-level selling points.
These include:
- Efficiency - Reducing the time needed to perform a given task or achieve a particular outcome.
- Cost reduction - Eliminating direct and indirect costs alike.
- Technical capability - Ensuring that our technical teams have the data they need to create new solutions.
- Resource allocation - Improving visibility into how effectively we’re using our resources
- Decision-making - Empowering leaders to take data-driven decisions.
- Innovation - Giving our team the data they need to innovate.
- Security - Reducing our vulnerability to all kinds of data-related risk factors.
This is quite a lot to contend with - but such is the importance of data for modern business.
To gain a clearer picture of how this works in practice, we need to dive deeper.
8 Types of data management solutions
Specifically, we need to survey the different kinds of data management solutions that we might be dealing with.
We said earlier that different platforms and tools might share similar overarching goals, but nonetheless, have very different focuses and specializations.
Therefore, we need to cover the primary categories that we can place platforms into. Of course, this is never going to be a perfect system. On the one hand, there will inevitably be variation within this categorization.
On the other, certain tools sit outside of our broad groups in classes of their own - as we’ll see a little bit later.
All the same, it’s important to understand to have a firm grasp of the different corners of the data management software market before we proceed any further with our buyers’ guide.
So, here are the eight big clusters of platforms.
Database management systems (DBMSs)
A DMBS is really the most fundamental cog in your data operations. Basically, this is the system that you use to format, administer, and maintain a given database. The most common examples are variations of SQL, a relational DBMS.
Relational here means that we can establish relationships between different data entities.
However - especially in recent years - it’s worth noting that SQL isn’t the only game in town. Instead, there are a multitude of different DMBSs that are suitable for specific applications, use cases, and data workflows.
We can’t give a comprehensive overview of these at the present moment, except to say that your choice of DBMS must suit your actual use case and data.
Besides, decisions around procuring a DMBS only really relate to a single data set and application, whereas we’re more concerned with the big picture of data management solutions.
Big data management
Big data is one of the big transformative business themes of the current decade.
Consultants love talking about it, but they don’t always bother to learn what it actually means. Basically, big data is how we deal with data sets that are too big or tasks that are too complex to be conducted with traditional queries.
From a technical point of view, this is quite a departure from your typical data management flows. So, we need to turn to tools like NoSQL databases, machine learning, and other novel solutions for dealing with high volumes of varied, unstructured data at pace.
Data warehouses and lakes
Data warehouses and data lakes are related, but with some important distinctions to separate them. What they have in common is that both are ways of creating centralized, accessible resources across the breadth of your organization’s data assets.
The difference is in the structure and application of these resources. Let’s think about each in turn.
First, data warehouses. These closely resemble a traditional relational database, with a column-based structure. Basically, creating a data warehouse means pulling information from a range of sources into one location - normally for the purposes of analysis.
This could be organization-wide or within a single vertical. So, you might ultimately end up with one single data source with all the information you have about your sales, inventory, locations, and products.
Data lakes are a little bit different in terms of their structure - or lack thereof. That is, data lakes more closely resemble larger versions of unstructured databases. A data lake is made up of a variety of data pools and objects.
These can be drawn on by different analytics platforms or even prepped for manual analysis by data scientists.
Data integration platforms
With all that data to deal with, the other big challenge is effectively utilizing this across different teams, platforms, and use cases. Most important - getting different data sources to work seamlessly together.
So, maybe you want to create a data warehouse or you simply want to let users compare values from two different platforms.
In either case, what we’ll need is a systematic way to pass information between platforms - along with performing any necessary transformation along the way. Data integration tools provide exactly this capability.
Increasingly, data integration tools are the beating heart of your business’s wider ops. With ballooning demand for custom software, strategic insights, and accessible data, it’s no wonder that there’s such an impetus to get platforms working together seamlessly.
Master data management
Master data management (MGM) is increasingly a huge priority for enterprises and IT teams in other large organizations. Master data is made up of consistent, uniform records on the core entities of the business’ data assets - like customers, products, suppliers, sites, etc.
The challenge of master data management, as you might expect, is creating and maintaining these master records. The goal is to provide reliable data sets for analysis, reporting, and strategic decision-making.
Since this is primarily a concern for enterprises, master data management normally involves dedicated platforms from blue-chip vendors. We’ll see a couple of examples of these in a few minutes.
ERPs, CRMs, etc
The tools you use for everyday business functions also play a massive role in your data management solution stack.
Many times though, this can fly under the radar.
We’ve picked out your ERP and CRM as examples since these are some of the most heavily embedded tools in your data ops. But - we could just as easily be talking about any other platform you use to collect, store, process, or share data on a large scale.
So what can we say about these?
The key is that - while these aren’t data management solutions themselves - they are central to a huge range of related workflows.
For instance, we’ll need to take into account common user interactions with these platforms to get a realistic picture of our present data management efforts.
Similarly, the technical capabilities of these platforms - particularly around integration and automation will also constrain our choices later.
Analytics platforms
Analytics is the stepping stone from raw data to useful insights. Specifically, analytics platforms enable us to aggregate, visualize, and make sense of our data. But, in the context of data management solutions, we need to make a distinction here.
See, plenty of tools offer some analytics capability - like a couple of charts within your inventory management software say.
A dedicated analytics platform empowers you to make sense of the full scope of your data assets - or that’s the idea at least. So, the goal is that end users can collate, aggregate, and visualize data from across your business, without necessarily knowing its exact source.
Depending on their needs and skill level, they might do this on the fly, or they might only interact with preconfigured dashboards.
Data-centric UIs
Finally, we can think about all of the interfaces that your team use to interact with data as data management solutions - this includes things like CRUD apps, GUIs, dashboards, forms, and other simple tools.
Now, we might have a hard time describing any single solution as data management software, granted. But, if we consider these in sum, alongside the tools we use to create them - then they fit our definition quite neatly.
And indeed, they’re a crucial component in your data management strategy.
The central challenge here is that the more we rely on data for daily tasks and decisions, the more we need reliable, efficient, tools for users to interact with this data. The tricky thing then becomes outputting suitable solutions at scale and pace.
For most businesses, this means relying on spreadsheets - although this is far from the ideal solution.

(McKinsey)
We’ll see how Budibase is changing the game here a little bit later by empowering IT teams to create custom solutions for managing their data faster than ever.
Example use cases
As we can see, there’s a huge variety of different solutions across the data management software market. Obviously, this speaks to the complexity and variability of data management as a field.
What makes this even worse is the fact that we’ll almost certainly want to utilize several classes of tools in concert with one another.
To make a better-informed decision about your specific real-world needs, let’s think through a couple of examples of data management software in action.
Here are some common exemplar scenarios.
We have more data than we know what to do with
This is an ever-more common complaint for organizations of all shapes and sizes. As more and more of our operations are digitalized, we accumulate a corresponding mountain of data.
Eventually, we reach a tipping point where we’ll need a comprehensive rethink of our data assets and how we manage them.
In this case, the first challenge is inventorying and documenting the data that we store currently - with a view to aligning this with what we need.
With this established, we can then think about centralization and any specific strategies we’ll use to ensure our data is accessible and usable. Don’t worry - we’ll cover these ideas in more detail when we start thinking about how to create a data management strategy.
Our teams don’t have the data they need
This is another very common pain point. Thankfully, it’s also an easy one to get your head around. Despite storing greater volumes of data than at any point in history, most companies struggle with getting it into the right people’s hands at the right time.
Naturally, this causes friction. However, we must also contend with the fact that we need to prevent our data from getting into the wrong hands at the wrong time.
So, to give an illustrative example, say your product marketing manager needs to pull figures relating to the ROI of an extended warranty program that you offer as an optional extra.
Although your company undoubtedly stores this information somewhere, it’s not guaranteed that the product team - or anyone for that matter - will know where to go and find it. Therefore, whatever decision they need to make will either get postponed or shelved entirely.
If we had an accessible, easily queried data warehouse, a navigable data catalog, a well-documented MGM platform, or even a clearer governance framework that helps departmental leaders collaborate, we could easily avoid this scenario.
We don’t know which sources to trust
When we talk about data management solutions, we’ll often circle back to the principles of consistency, authority, accuracy, and validity. These are central to effective data management for a few reasons.
One is the fact - for any given metric - there’ll often be several different ways of conceptualizing, operationalizing, or gathering the relevant data. This can lead to us having multiple conflicting values for the same attribute.
Say for instance, we tried to pull a sales figure for a given month from our ecommerce, billing, inventory management, and CRM platforms all at the same time. Hopefully, they’d all add up, but there’s a strong chance there’d be some variation between them.
This could come down to quirks in the individual systems or someone getting something wrong along the way.
Either way, we can use a variety of data management solutions and strategies - either to maintain consistency between platforms or to ensure that one data set is retained as our authoritative source of truth.
Our teams are operating in silos
The bigger your organization is, the greater the chance that employees in one department will have no idea what their colleagues in other teams are up to. It’s bad enough trying to keep up with projects within our own teams.
In terms of data assets, this creates a couple of distinct, wholly avoidable problems.
These are all variations on one team not knowing what data another one stores and/or needs to access.
So, your marketing team might be sitting on a raft of insightful data that their sales colleagues could be using - only it’s in a local spreadsheet somewhere that they never thought to tell anyone about.
One obvious potential outcome is that the sales team simply goes without this information. Or, they might waste time collecting it for themselves - in which case we might end up with duplicates of the same data sets - or worse, conflicting entries for the same core objects.
Therefore, centralization, collaboration, and de-siloing are urgent priorities for data management improvements.
We’re wasting money on pointless data admin
Administrative tasks are like death and taxes - they’re inevitable. But, that’s not a good reason to subject colleagues to them all day every day. When we have ineffective data management measures in place, we’re more likely to suffer from this problem.
Again, this is obviously proportionate to the scale of our data assets as well.
Basically, there’s always going to be some need for manual interactions with our data - like manually updating, deleting, or creating an entry.
However, for efficiency’s sake, it’s imperative that we eliminate the need for manual interactions wherever possible, and streamline remaining human interactions as far as we can.
For example, with a mixture of automated data pipelines, platform integration, and intuitive user interfaces for specific data management actions. Again, we’ll see some tools that will help us along the way shortly.
We’re worried about security/compliance/privacy issues
Finally, we can’t underestimate the role of security in our decision-making around data management solutions. We’ve said it before and we’ll say it again - data security is a top risk factor for businesses of all sizes.
The reality is that we face a perfect storm.
We know that we have bigger, more complex data sets to deal with - alongside more frequent interactions with these from different actors - so there’s a huge risk of human error.
We also need to contend with an ever-more restrictive regulatory environment and nefarious actors around every corner.
In short, the stakes are higher than they’ve ever been.
The implications for our choice of data management tools are clear. That is, security, privacy, and compliance must be factored into our every decision. In practice, what this means will vary from organization to organization.
We’ll see some core features of our top picks a little later.
8 benefits of improving data management
Before we can move on to creating a data management strategy of our own, it’s useful to more thoroughly explore what we can achieve. Any change management initiative is only as good as the goals that we set for it.
And to set goals, we need to know what the measurable, specific benefits of improving our data management are.
We touched on some of these briefly when we talked about the role of technology.
Now, we’ll think about some of those familiar ideas and some new ones in even greater detail.
Cost-effectiveness
Hopefully, we don’t need to explain what this means in any great detail. If we’ve made one thing clear so far, it ought to be that we can use improvements to our data management systems to either reduce costs, improve outcomes, or both.
As you might expect, these are also the two most basic types of goals you can set for your transformation efforts.
Luckily, they’re also relatively easy to quantify - both for measuring our current performance and setting targets for where we’d like to get to. Certainly, this is the case for direct costs and outcomes.
To gain a fuller picture though, we’ll also need to consider their indirect counterparts.
We’ll see some of the most important elements therein as we flesh out the next few issues.
Agility
Agility is how effectively your organization responds to changing circumstances - whether this is an emerging threat, a sudden incident, or slower, more incremental shifts in your target customer’s preferences.
The role of data here can’t be overstated.
Whenever we encounter any kind of change or incident, our first priority is establishing what has happened and how it impacts us. Obviously, if data is important, it follows that data management is too.
Anything we can do to improve the speed and ease with which relevant teams can access information, the better. So how do we set goals around agility?
As ever, we need specific metrics that we can focus our efforts on. For instance, incident response times, resolutions to feature requests or the costs associated with different known risks and threats over time.
Collaboration
Improving collaboration is one of the most fundamental aims of data management solutions. This is because a basic prerequisite of collaboration is a shared understanding of the facts.
When we improve the accessibility, reliability, and relevance of our business data, we provide exactly this for our colleagues. We can think about this at a much more tangible level too. Take maintaining a particular data set for instance.
Centralization of a master version is obviously a prerequisite here.
Beyond this, effective data management solutions also provide the broader capabilities that make collaboration viable - including version controls, audit logs, and real-time updates.
Strategic insight
How often do we hear businesses nowadays talking about being data-driven? Certainly, this is a priority for just about every organization, but how many of them actually walk the walk? More to the point - what does being data-driven really mean?
One way of framing this is in terms of strategic insight.
That is, a data-driven approach means taking our cues from what we can empirically know based on the data assets we hold. This might seem obvious, but if we scratch beneath the surface, there’s more to it than you might initially think.
The real killer here is scale. Just think, it’s easy for one person to consult the data and make an informed decision on one issue. To be data-driven, we must establish this as the norm across all decisions, organization-wide.
There’s no two ways about it - that’s an enormous undertaking. In the first instance, even collating and warehousing all of the data that anyone - from the C-suite to your marketing team could need - for any decision - is a mammoth task.
Then, presenting this in an accessible, readable, and useful format for different user personas adds another layer of difficulty on top of this.
As you can no doubt tell, this is a wholesale transformation of the way we do things, rather than a purely technical initiative.
Technical capability
Effective data management solutions will also boost our technical capabilities and capacity for digital transformation in the medium to long term.
How?
Data is obviously the basic currency of digitalization. In order to transform any process, workflow, or task, we must be able to represent its constituent elements as data objects or entities.
Therefore, by systematizing our business’s treatment of data assets, we can transform more and more tasks.
Specific data management solutions will also have more granular impacts on our technical capabilities. For instance, performance enhancements that come along with specific data architecture or infrastructure projects.
Another element of this that’s a little bit less obvious but growing in importance is the fact that improving access to data across our organization also widens the pool of colleagues who can create technical solutions.
For example, if you want to successfully roll out initiatives like citizen development or adoption of low/no-code tools, then effective data management solutions are an important prerequisite.
Resource allocation
Resource allocation is essentially a sub-category of data-driven decision-making. In fact, this is the most basic type of strategic decision there is - determining which initiatives are worth our time and money - and how much each one needs.
But what role does data play here?
Actually, we can point to two distinct levels at which our data management solutions impact our resource allocation.
First, when we have more reliable information about our internal costs and the return they provide, we can more easily make rational decisions about how to allocate resources.
Secondly, we’ll also, almost inevitably, end up with more resources that we can allocate. Think about it, we said earlier that the primary thing you can achieve with data management is cost-effectiveness.
Therefore, it only follows naturally that, in doing so, we’ll free up resources that we can then reallocate to other areas that need them. And fingers crossed, we end up in a bit of a virtuous circle.
Risk management
We’ve alluded to this already, but it’s still worth thinking about how we can set goals around risk management. By their nature, risks are things that have the potential to cost you if they occurred.
The trouble here is that it’s very tough to quantifiably measure changes in how likely something is to happen.
One option is obviously to focus on incidence rates. So if we do something with the intention of reducing the risk of a particular incident occurring and it starts happening less often - we can be pretty confident we’re on to a winner.
More often though, we’re going to focus on the costs associated with managing different data-centric risk factors - like breaches, cyber-attacks, compliance issues, and other related incidents.
This actually allows us to attack the problem with a great deal more precision.
For instance, if we decide to focus our efforts on the labor hours and associate costs of compliance vetting, usage auditing, or more technical security activities.
Soft-issues
Finally, there’s a huge variety of more human-centric areas where strong data management solutions will pay massive dividends. After all, we’re ultimately trying to make our colleagues’ professional lives easier, better informed, and more productive.
It’s only natural that this will have a measurable impact on them.
For instance, they might be more satisfied in their work, because they get to spend more time on rewarding, innovative tasks or more clearly see the results of their labors.
It’s worth noting that - while this is undoubtedly a common effect of data management improvements - it’s unlikely to be our primary goal. Still, we ought to know the kinds of human-led metrics that we can pay attention to.
For instance, retention rates, results of employee satisfaction surveys, or even levels of interaction with the tools and data that you provide.
5 data management challenges
Unfortunately, with data management software, we rarely have the risk of simply buying an off-the-shelf solution, rolling it out, and living happily ever after.
In the real world, things are rarely this simple.
Instead, the truth is that we’ll encounter new risks and challenges that might not otherwise rear their heads when we begin thinking about data management solutions.
So, to make an informed procurement decision, we obviously need to grapple with these too.
Here are five of the biggest issues you’re likely to encounter.
Compliance & regulatory issues
It’s no secret that the regulatory landscape around privacy and data protection has never been more stringent or complex. Unfortunately, the more data we store and process, the more we expose ourselves to this.
So, we have obligations under formal regulatory instruments like GDPR, PIPEDA, and an ever-growing list of their counterparts across different regions and states. Then we also have to contend with internal compliance.
For instance, internal policies and self-certification around data usage, lifecycle, and access - as well as rules relating to how and when we can work with different vendors. More on this latter point in a second.
Project spillover & scope creep
Spillover and scope creep are two related yet subtly different phenomena. But - unfortunately - both have the potential to torpedo your change projects with rising costs.
So listen up!
Spillover is when we set out to improve, digitalize, or otherwise transform one area of our business, only to find out that it has unforeseen dependencies, which will therefore also require our attention.
For instance, if we wanted to build a data warehouse for our sales department, but we realized that we’ll never have all of the data we need for this without extensive digitalization of our customer support team.
Scope creep is when our project requirements balloon or expand, without necessarily being related to dependencies. So, the equivalent situation would be if we started building a data warehouse for sales and then someone decided support needs one too.
Some extent of both is normal - or at least manageable.
However, when not kept in check, escalating costs can easily undermine our projects’ viability.
Internal blockers
Internal blockers are colleagues - regardless of their level - who seek to put the brakes on our efforts. This is a factor in any change project, but it’s a particularly big issue when it comes to data management solutions.
Let’s think about where we might encounter some of the blockers and what their contentions might be.
We can’t dedicate too much space to thinking about this, so we’ll broadly categorize them into leadership blockers and on-the-ground blockers. An example of the former could be a CFO who’s worried about excessive costs or opening ourselves up to new, undocumented risks.
If we don’t get buy-in here, our project is unlikely to go ahead.
Then the latter could comprise your on-the-ground teams within departments, who are concerned about changes to their responsibilities, or even excessive micro-management.
In both cases, the important thing is to find ways of genuinely addressing the concerns of internal blockers to secure buy-in across your organization.
Vendor-side challenges
In large organizations, purchasing decisions around new data management solutions are constrained by internal rules around vendor relationships.
Consider for a moment how fundamental and embedded data management software becomes in your internal operations. Therefore, the risks that come along with working with external partners are even greater than in the case of other software solutions.
What are these risks?
Say we find one particular platform so useful that we build our entire data ops around it - that it literally plays a role in every decision we make as a business. If the vendor suddenly upped their prices, we wouldn’t have much choice but to cough up the difference.
If they suddenly went out of business or sunsetted a feature that we rely on, we’d similarly be in a very tricky situation.
This is called vendor lock-in. You can see why preventing this is a top priority for enterprises - with common strategies including prioritizing open-source and self-hostable solutions, along with multi-year licensing and support arrangements.
Finding talent and expertise
Finally, you may have gathered so far that data management is by all accounts a complex, interdisciplinary beast. Even if we recognize the need for change, there’s no guarantee that we are going to have the in-house know-how to make this a reality.
As we’ve mentioned, it’s not as if we can simply buy a particular platform and reap the rewards.
Rather, even coming up with a list of requirements and researching the market is a big undertaking - let alone configuring and ultimately managing whatever solution you settle on.
Of course, we always have options. For instance, we can upskill internally, hire for the talent we need, or rely on consultants and external vendors. Each comes along with its own risks and benefit, so this requires some careful thought.
Top 6 data management software solutions for 2023
We’ve covered a huge amount of theory so far, as well as the specific steps you need to take to settle on the best data management solutions for your specific needs.
But, our discussion wouldn’t be anywhere near complete without checking out some of our favorite options on the market today.
In no specific order, we have:
![]()
Posthog
We’re starting with Posthog because we think it’s a real game changer for gathering, analyzing, and visualizing data relating to your users and how they behave within your product.
It’s a comprehensive suite of open-source data management tools, comprising API management, event flags, data warehousing, access controls, reporting, and much much more.
We particularly love Porthog’s easy configuration and SQL-like query syntax, which makes onboarding a breeze for IT teams.
![]()
Snowflake
Sometimes a platform comes along that becomes completely synonymous with one particular use case. For cloud data management, that platform is Snowflake. Increasingly, it’s just the way businesses manage their data in the cloud.
With an enormous ecosystem of collaboration, visualization, application building, data engineering, architecture, and warehousing tools, Snowflake offers extensive functionality across the full spectrum of data management solutions.
You can see why Snowflake has carved a niche as such a ubiquitous full-stack platform. However, if you only need certain, specific functionality for your transformation efforts, it may be more cost-effective to look elsewhere.
![]()
Oracle CI
We can also think about some of the more long-standing players in the data management software game. Oracle is the most obvious example here.
Specifically, the Oracle Cloud Infrastructure ecosystem is probably the most established enterprise data management system around - with everything from data lakes and warehousing to containerization, application layer, and DBMS functionalities.
Check out our Oracle integration page to learn more.
![]()
SAP
SAP is the other brand here that’s something resembling a household name. For enterprises, SAP data management solutions are really just part of the furniture at this point, offering MDM, governance, integration, and data fabric solutions - to name but a few.
Again, this is a suite of tools that becomes highly embedded within your organization.
So, this can be a viable option if you’re looking for an all-encompassing solution, but may be less appealing if you’re requirements are more focused on flexibility or adding more specific, granular capabilities.
![]()
S3
Amazon S3 is a slightly different proposition from the other data management tools we’ve seen so far. Rather than a complete end-to-end solution, S3 is a secure, scalable, and flexible object storage solution.
The idea is to provide a platform for storing large volumes of data for diverse use cases, including data lakes and warehouses, as well as applications, websites, backup and recovery workflows, and even resource planning.
Even better, S3 is a fully-configurable data source within Budibase - the perfect pairing for effective data storage and application building.
![]()
Microsoft MDS
Finally, we have Microsoft MDS - the tech leviathan’s master data management solution within SQL server. As we know MDM is all about creating accessible, centralized, and ‘official’ versions of particular data sets within your organization.
We’ve chosen MDS as our exemplary master data management solution because of the ease with which you can add rules, modeling, and access controls to existing SQL data sets - after all, SQL is the basis of innumerable business data processes.
Since MDS is within the Microsoft ecosystem, you’ll also enjoy a high level of integration with other platforms, including Excel, PowerBI, and Dynamics.
Who benefits from data management solutions?
We’ve seen at length just how impactful data management software can be across an enormous range of internal issues.
But, it’s also worth thinking about the more concrete ways that this can influence the daily work of colleagues within specific teams. It’s obvious that different departments will have their own relationships with various data assets.
So does everyone stand to gain equally from improvements here? That’s before we even consider stakeholders outside your organization.
Let’s dive in.
IT
Obviously, technical colleagues are the ones who will be most heavily and directly impacted by any changes to your internal data operations. No surprises here, given that the IT team are the ones who are already responsible for this - at least in theory.
With improvements to automation, efficiency, oversight, and accessibility, we’ll undoubtedly see improvements in our IT colleague’s productivity levels.
However, with centralization, there’s a good chance that we’re actually creating a lot more work for the IT department - at least in the first instance. It’s a big shift from individual colleagues and departments storing spreadsheets locally to full-on warehousing and MDM.
IT are also the ones who are going to bare the brunt of associated costs, across procurement, management, maintenance, and LCM of any new tools we opt for - whether this is labor hours, opportunity costs, or equipment/licensing.
This isn’t a problem as such, but it’s a reality that we’ll need to contend with nonetheless if we want to provide appropriate resourcing to our data management efforts.
Operations
The picture is a little bit different within the operations department. You see, the nature of this team means that they have a very different relationship with internal data than their IT colleagues.
And of course, this is reflected in their specific priorities and interests within transformation projects.
The main boon that ops professionals will enjoy is improved oversight and insight.
For a simple example, let’s say you were an operations manager in an international B2C, product-focused business.
One of your core challenges will undoubtedly be maintaining visibility over finished products and raw materials as they move throughout your logistics network. The right data management solutions will lend a hand at a couple of interrelated levels.
First, there’s the issue of collating all of the required data sources - potentially from warehouses, retail locations, and fulfillment centers around the world.
Then, as ever, we need to provide this data as actionable insights for users in a performant, accessible, and intuitive format.
Ultimately, the upshot is that our ops team can make better informed, faster, and more profitable decisions.
Legal, finance, and HR
We could say a lot of things about our legal, finance, and HR colleagues - but there’s no denying the fact that these are heavily process-driven parts of any business. That is, for one reason or another, there are established ways that things need to be done.
Most of the time, we’re trying to ensure compliance with some internal or external rule. And the stakes are high too.
How this fits in with data management might not be as immediately obvious as in our previous examples, but stick with us.
The really critical factor at play here is the accuracy of the information that we base our processes around. None of our processes, policies, or other governance instruments are worth the paper they’re written on if we apply them to poor-quality data.
So, on the one hand, we’re improving outcomes, by reducing the risks of things going wrong based on incorrect information. We’ll also see efficiency dividends from giving our teams fast, easy ways to search and look up data.
These are our fundamentals.
Of course, these are also notoriously paperwork-heavy departments. Data management software also empowers us to make these teams’ lives easier and more productive including providing the capability we need to eliminate manual tasks through automation.
Commercial
We’ve spoken already about the fact that how you manage your data is intimately tied up with your wider profitability and cost-effectiveness. So much so that we’d have serious difficulty even beginning to disentangle this relationship.
One thing we need to do, however, is think about how all of this impacts the teams that are actually responsible for bringing in the money. The commercial arm of your business - largely made up of the sales and marketing teams.
This is actually one of the more exciting end-uses that we can point to.
Consider for a second the nature of the decisions that these colleagues need to make on a daily basis. What’s unique here is the extent to which we’re always relying on imperfect information.
Sadly, all the data in the world won’t get us inside the heads of our customers and prospects.
However, the more information we have about our target customers, the better we can predict their needs, wants, and behavior. Doing this effectively across the full spectrum of modern sales and marketing channels is probably too big a task for non-technical colleagues.
Therefore, tools like data warehousing, pipelines, MDM platforms, integration, and automation play an enormous role in empowering our commercial teams with the insights they need to gain a competitive edge.
Leadership
Internal leaders - from department heads all the way up to the C-suite - have their own data management priorities too.
The real killer here is time.
The head of any given department doesn’t need the same granular level of detail about a particular issue as an on-the-ground specialist does. They need to know the strategically relevant facts, quickly.
Organizational leaders - ie the people at the very top - have similar priorities, but across the entire business.
However, from a technical point of view, we’re often not that heavily burdened here. The thing is, there’s actually a very high degree of regularity to the data insights that senior leaders require.
So, there might be a limited, known set of data points that we need to present, the key is ensuring that leaders can access these quickly, from wherever they are.
Customers
Finally - and admittedly a little bit more counterintuitively - we can think about how your choice of data management solutions is going to impact your customers, clients, and other third parties.
There are countless different permeations of how this could play out.
We can place these into a few broad camps though - based on the core issue addressed. One is customer experience. Or vendor/partner/supplier/client experiences, as the case may be.
Without a doubt, efficiency is the biggest priority for pretty much every customer interaction - for you and for the customer.
Why?
On our side of the equation, speedier resolutions mean lower labor costs and higher conversions. Customers love efficiency too because it minimizes the effort they have to put in to see value from whatever product or service they’re buying.
We can apply the same logic to aftersales interactions too.
So, when we resolve service and support issues as quickly as possible - with minimal input from the customer - we’ll see lower associate operating costs - and potentially increased retention rates.
Building a data management strategy
It’s time to think more concretely about how to put what we’ve learned so far into action. We know, for example, that we can think of shopping for data management software as a procurement exercise, but that’s not the whole story.
Because of how deeply embedded data management platforms can become in your ops, we can also frame this as a type of transformation effort.
Therefore, whether we’re opting for a commercially available tool or a custom build, we’re going to need a clear procurement and implementation strategy in order to provide actual business value for our end users.
With that in mind, here’s how we can create a data management strategy in 8 steps
1. Auditing and discovery
First of all, we need to establish where we’re starting from. Basically, how do we treat internal data at present? This is a deceptively complex question. See, it’s unlikely that there’s going to be a uniform answer across the entire business.
We won’t worry about the specific data that we store just yet. That comes next.
For now, we can think in more abstract terms. The goal is essentially to outline the strategy, process, governance, and systems behind how your business collects, stores, processes, and uses data at present.
Obviously, we can’t give a comprehensive account of every possible permutation of this.
Broadly though, you’ll want to answer the following questions:
- Do we know what data we’re storing?
- How is this collected/stored/processed?
- Who controls our internal data?
- How is data shared across our organization?
- Can colleagues access the data they need?
- Can they access data they don’t need?
- Can we ensure the accuracy/validity/integrity of data?
- Who decides when data is created/updated/read/deleted?
- What does it cost us to manage our internal data?
- What return do we see from this cost?
But where can we get this information? Realistically, we’ll almost certainly need a mixed-methods approach here. So, we’ll undoubtedly see value from traditional auditing within our existing core infrastructure.
However, to get a fuller picture, we’ll also need more qualitative tools - including employee surveys.
2. Inventory data assets
Once we have a better understanding of how our present data management strategy operates, we can move on to more specific data. Before we can go any further, we need to know what data our business currently stores.
Then we want to figure out what data we don’t have that we ought to.
One thing at a time though.
Obviously, detailing every piece of data that your entire organization holds has the potential to be a bit of a herculean task. You’re going to need some means of discerning what’s important and what’s not.
For instance, we care about actual sales figures from October 2020 - we don’t care what Gary from sales had for lunch that month.
The key, therefore, is to create a working conceptual model of your organizational data. This begins with an inventory of the data entities that we need for our internal processes - things like customers, locations, employees, products, etc.
Then for each entity, we need to know which attributes we store (or ought to) - in other words, what we want to know about them. For our customers, this could be aspects of their demographics, behavior, history, and preferences - for example.
We can complete our data model by fleshing out the relationships between each of our entities. An example might work at a certain location. A location can carry certain products. Etcetera, etcetera.
This is only a cursory explanation. Check out our more in-depth guide on how to create a data model for a fuller discussion.
3. Map your data flows, roles, actions, and access requirements
Next, we can think more about how data is used in the real world. Who needs it, what for, and how it moves across different teams, departments, colleagues, and platforms within our organization.
Again, we’ll take actual in-situ processes as our point of departure - because, again, things are unlikely to be uniform across the organization.
So, we can start by analyzing the platforms that are used to transfer data in repeatable or uniform tasks. For example, the tools we use to pass our online customer’s details around from our ecommerce platform to eventually fulfill their order.
We’ll also need to take a step back beyond this, however. Remember, one of the core goals of data management software is to improve the ease with which our colleagues can access, share, and collaborate with data.
We can also think about which specific employees and teams need to take different actions within processes, and what levels of data exposure they therefore require.
So how does this work in irregular scenarios - like if our head of sales requests some figures from their marketing counterpart? Do they meet in a hallway to hand over a floppy disk? Do they email a spreadsheet?
Or can they both already access the same master platform?
4. Set goals
With a clear picture of where we are and where we’d like to get to, we can set goals for our data transformation solutions. This is an important step for crystalizing what we want to achieve as well as giving us the means to measure our progress.
Luckily, we’ve already covered a large proportion of what you need to know here.
Cast your mind back to the practical ways the business-level impacts of effective data management that we outline earlier - cost reductions, efficiency, risk management, accuracy, strategic insight, etc.
Knowing what we learned about our existing processes in the previous steps, our task here is to decide what specifically about our data management efforts we want to improve upon.
Critically though, we need specific, measurable goals for these to be valid.
5. Storage, architecture, and infrastructure
Then we can start thinking about actual platforms, solutions, and software. For our purposes today, we’re breaking these down into three clusters. Depending on your particular situation and goals you might need to think about tools within any combination of these.
The first is data storage, infrastructure, and architecture.
This includes everything from hardware, networking, and hosting solutions, to DevOps, cloud technologies, and even access management.
Gain, it would be almost impossible to give a comprehensive account of everything you might need to think about here.
Instead, here is just a selection of the questions that you will want to answer:
- What volume of data do we need to store, transfer, and manage?
- Where will we store our data?
- How many users will we deal with?
- What are our security/authentication/access requirements?
- What are our other non-functional requirements?
- What resources do we have to dedicate to this?
- Will we manage our infrastructure in-house or contract this out?
6. Processes, pipelines, and integrations
The next category of tools we’ll think about relates to how we actually action particular processes and tasks, along with how data moves around between different locations, platforms, users, and other nodes in support of this.
One way to think about this is that we’re implementing the data flows that we mapped a few minutes ago. Well. Finding the best way to implement them and then implementing them.
The scope of the market here is pretty vast - in terms of target users as well as functionality. So, we have developer tools like API managers and then we have more accessible platforms that allow users to integrate existing tools, without huge technical skills.
As we’ll see when we round up specific tools in a couple of minutes, this can also include the platforms that you’ll use to configure usage, access, warehousing, and lifecycle management of your data, as well as building automations, rules, and aggregation.
7. User interactions, interfaces, and internal tools
Finally, the third cluster of data management solutions we’ll need to plan for are the tools we use to facilitate everyday user interactions. We’ve stressed over and over again that your data is only as good as the business value that flows from it.
Admittedly, this is the slightly less exciting - but no less crucial - side of data management.
The crux is we need tools that let us empower our users to take the actions and draw the insights they need.
These can come in a few different forms.
One neat category is presentation tools like dashboards or visualization platforms. They play two roles - allowing some users to configure reports and others to access insights.
Then we have CRUD tools, which allow users to create, read, update, and delete specific data entries - for example within data entry workflows.
And finally, we have internal tools. These are usually custom solutions that allow employees to carry out defined data management actions within specific workflows. For IT teams, the real killer is building these at scale and pace, leveraging myriad different data sources.
8. Monitoring, maintenance, and continuous improvement
Whichever data management tools we opt for, it’s unlikely that we’ll be able to simply buy them and then watch the money pouring in. Rather, since this is a major transformation initiative, we’ll inevitably need ongoing monitoring and optimization.
In the short term, this is a sort of bedding-in period. So, our primary concern is with how effectively we’re achieving our required technical capabilities - is our implementation going according to plan?
In the medium-to-longer term, we need to monitor how we’re progressing toward our overarching goals - whether these are monetary, temporal, process-based, or some other type of objective.
The important thing here is not so much to get a yes or no answer about whether we’re on track. Rather, we must adopt a continuous improvement mindset - using our KPIs to constantly find opportunities for ongoing improvement and optimization.
Manage internal data with Budibase
More and more businesses are turning to low-code platforms to support their data management efforts. As our reliance on data grows, so too does the demand for professional, intuitive interfaces to interact with it.
This puts a huge strain on IT teams to keep up with the number of internal solutions they need to create.
Budibase is the fast, easy way to build custom applications using just about any data source you can imagine.
Here’s what makes our platform tick.
Our open-source, low-code platform
Budibase leads the pack for open-source, low-code application development. Thousands of businesses around the world choose us for flexible data support, incredible design tools, and painless deployment and maintenance.
Check out our features overview to learn more.
External data support
No other low-code tool comes close to Budibase for external data support. We offer dedicated connectors to let you build apps using SQL, Postgres, Airtable, S3, Oracle, Mongo, Couch, Arango, Google Sheets, Rest, and much, much more.
We even offer our own built-in database with full support for CSV uploads, if you want to build your data layer from scratch.
Self-hosting
You’re in control of where and how you host your Budibase tools. Deploy to your own infrastructure locally or in the cloud with Kubernetes, Docker, Docker Compose, and Digital Ocean.
Alternatively, use Budibase Cloud and let us worry about everything. Take a look at our pricing page to learn more about both options.
Custom plug-ins
Budibase also offers unrivaled customization and configuration. Use our dedicated CLI tools to build and deploy custom components and data sources across your entire ecosystem of low-code solutions.
Check out our plug-ins documentation to learn more.
Configurable RBAC
Maximize security and usability in one stroke with our configurable role-based access control tools. Grant or restrict access at the level of data source, queries, screens, or individual components.
With Budibase, it’s never been easier to build applications that reflect your existing data access policies.
Intuitive automations
Build complex automation rules, without writing a single line of code. Budibase offers an intuitive, flow-chart-based automation builder interface, with a huge array of nestable, combinable built-in actions.
We also offer extensive third-party integrations, with Zapier, Rest, Webhooks, and more.
50+ free app templates
We have huge confidence in what Budiabse is capable of. But why should you take our word for it?
Check out our library of over fifty free, deployable, and fully customizable application templates to see our platform in action.
To start building data management solutions the fast, easy way, sign up for Budibase today.