
Data automation is one of the most transformative strategies that your business can turn to. Separately, data and automation are two of the biggest priorities for modern business IT leaders.
So, it follows quite naturally that automated data processing offers enormous benefits - for IT teams, on-the-ground employees, and the organization as a whole.
Today, we’re going to dive deep into everything you need to know. We’ll start by covering the basics, including what automated data processing is, what it looks like in practice, and what it achieves.
Then, we’ll look more deeply at how you can make this a reality, along with all of the technical, operational, and cultural considerations you’ll need to make along the way.
But first, let’s answer the most pressing question of them all.
What is data automation?
Data automation - as the name implies - means using automated technology to replace or otherwise support manual interactions within your data management efforts.
What kinds of interactions are we talking about here?
Managing and maintaining business data across its lifecycle requires a huge effort - including collection, validation, storage, processing, access, analytics, security, day-to-day management, and much more.
The idea is that we eliminate the need for human interactions wherever possible, and make those that remain as efficient, streamlined, and quick as possible.
That way, your employees can focus on using your data assets to create value, rather than spending time carrying out menial tasks manually.
Most often, data automation is built around the ETL framework. This means expressing your automating efforts as comprising three parts:
- Extract - Actions relating to how you collect, gather, or transfer data from various sources.
- Transform - Actions performed on the data itself including reformatting, aggregation, restructuring, or any other transformations and processes.
- Load - Transferring data between platforms to facilitate further processing or access, either manually or automatically.
This demonstrates a very important point. The most ubiquitous types of data automation relate to how we facilitate the flow of data across our organization - although this is far from the whole story.
That leads us neatly onto…
Types of data automation
Automated data processing can actually mean wildly different things in different contexts. Therefore, it’s valuable to think about how we can categorize different types of solutions based on their core use case.
Here are the broad clusters of actions that we apply data automation to.
Admin tasks
We’ll start with the most basic type of automated data processing - simple administrative tasks. An enormous proportion of admin actions can be expressed as some variation on the basic CRUD operations.
So, for almost all data entry tasks, we’re creating a row in a database. Other basic admin tasks might require some combination of read, update, and delete operations.

(Zapier)
These are incredibly simple actions from a technical point of view, but they still frequently eat up huge amounts of resources to perform manually. Therefore, automating them breeds huge efficiency savings.
Of course, what this means in practice can vary hugely.
For example, the work needed for automating a data entry workflow will depend on the data set’s complexity, the source of the new information, the extent of human judgment that’s required, and many other factors.
Repeatable decisions
Next, we have tasks that mainly comprise applying defined rules and logic to data. We’ll think about how this works in generic terms first and then how we can apply it to real-world situations.
By their nature, regular tasks rely on repeatable decisions. So, we have particular values that are assessed, and if a defined condition is met, a follow-on action can go ahead.
The easiest example of this to wrap your head around is request/approval workflows.
These involve one set of users making a request by providing relevant information. In a manual process, another user might then assess the information provided, and make a decision, based on defined rules.
Data automation offers huge efficiency dividends here, by removing the need for regular decisions to be made manually.
Check out our guide to invoice automation for one set of practical examples.
Moving and transferring data
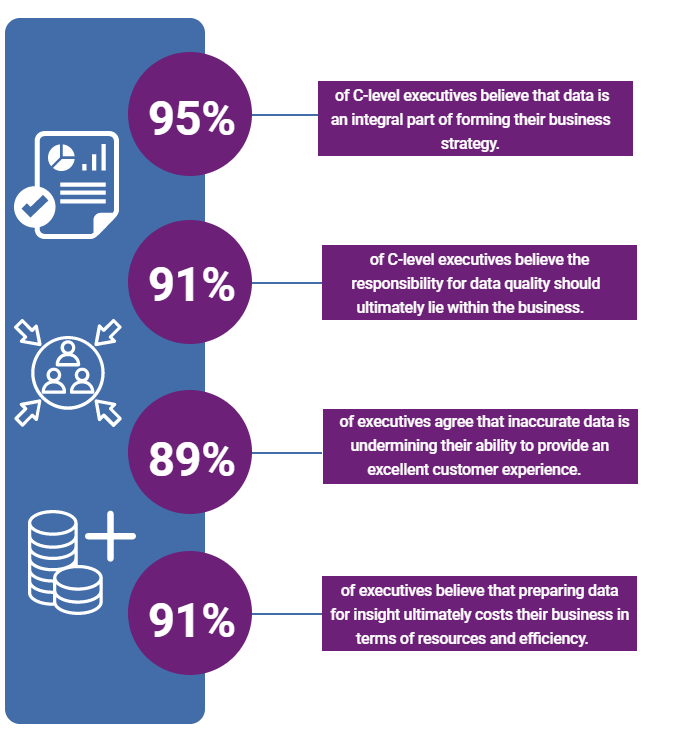
Transferring data between platforms is much more complex from a technical point of view, but still offers huge benefits in terms of providing sleeker, more cost-effective internal processes. As you might expect, the thing we want to avoid is colleagues needing to do this manually.
This takes time - often from highly skilled employees - as well as creating an excessive risk of undermining our data’s consistency, integrity, security, validity, and other critical issues.
Obviously, none of this is ideal.

(EDQ)
{kind=link}
Automation provides a clearly preferable solution. When we use automated data processing, we eliminate the need for costly, risk-laden transfers, as well as hugely enhancing the scale that we can carry tasks out at.
Nowadays, the big topic under this umbrella is automated data pipelines. This means creating predefined flows of data between source systems and target repositories - for instance, moving local data from individual locations to a centralized, cloud warehouse.
The idea of pipelines is to automate any transformations or other processing that are required to port the data in question.
Centralization, data warehousing, and data lakes
Let’s think more deeply about centralization. Oftentimes, this is an objective in itself. That is, we might explicitly set out to improve visibility, control, and ease of access within our data ops by creating centralized resources - including data warehouses or lakes.
See, businesses nowadays store a greater volume of data than ever before - often more than they can really handle. So, we end up with data assets being stored and managed in different ways across the organization - with little coordination.
Centralization plays a critical role in empowering your team to leverage your data for maximum value, as well as facilitating more effective security, oversight, and accountability measures.
The role of automation here can’t be stressed enough. Indeed, the scale of the tasks of creating and maintaining data warehouses and lakes is such that it would simply be unviable without automated data processing.
Transformations and set processes
We can rely on data automation to expedite any repetitive transformation or processes, even outside of the context-specific use cases we’ve seen so far. This could be something as simple as marginally altering a value in a defined, repetitive fashion.
Say, removing an area code from a phone number or incrementing a numerical attribute based on some defined event.
The point is that if we need to do something to our data over and over again, then we’ll more than likely benefit from automated processing.

(McKinsey)
We can go after these kinds of efficiency savings at a few different levels - largely depending on the scale and frequency that we require the actions in question to be applied.
For example, we might use user actions or back-end events to trigger automated transformations, depending on our needs in a specific use case.
You might also like our guide on how to create a workflow model.
Security, back-ups, and monitoring
Automated data processing is also a crucial element of modern security practices, and DevOps more broadly. For example, tasks related to threat detection, issue monitoring, back-ups, validation, auditing, and more.
Many of these simply wouldn’t be possible to conduct effectively with manual interactions.
Besides this, other types of data automation breed better security by limiting user exposure, cutting the scope for human error, limiting attack surfaces, and enhancing visibility over how data assets are used.
Similarly, automation plays an important role in maintaining the validity and integrity of our data assets, as well as ensuring compliance with relevant regulatory requirements.
In fact, with the scale of modern businesses’ data assets, it’s unlikely that your security efforts will be effective without some automated component.
Analysis, aggregation, and insights
And finally, we have automated data processing that relates to how we garner insights from our assets. Again, the killer challenge here is that businesses often have more data on-hand than they know what to do with.
One way that this can play out is that your team will struggle to make decisions based on the information they have available to them. An increasingly important use case for automated data processing is helping us to make sense of the information in front of us.
There are a couple of key levels to this.
Our first challenge is collating all of our organizational data into a usable form. We then need the capability to translate this into insights that can actually inform our decision-making.
At this point, we start crossing over into the realms of data science, so it’s important to stay on topic and think broadly about what data automation brings to the table here.
A basic example would be automated reporting on key performance metrics.
Or, we might leverage more advanced strategies, including machine learning, to garner insights from large data sets.
Benefits and challenges of automated data processing
So, now we’ve seen the broad scope of what data automation can mean in practice. And broad really is the operative word here - as we’ve seen automation can play a huge range of different roles across your IT and ops teams.
Therefore, when it comes to making an informed decision about the right tools and strategies for your needs, it pays to have a good grasp on the business-level impact we can hope to achieve through automated business processing.
In other words, what specific benefits and challenges can we expect here?
Let’s dive right in.
Benefits
We’ve already alluded to a lot of the headline factors that lead businesses toward data automation. Still, it’s worth spelling out the key points a little more explicitly so that you’ll have a good grip on what you’re hoping to achieve.
To a large extent, we can relate just about every aspect of this to efficiency.
Of course, we can flesh this out into a few more granular issues across our data management processes, including:
- Cost-effectiveness.
- Time to completion.
- First-time resolutions.
- Incidence of delays, errors, or other issues.
- Accuracy.
We can also point to marked reductions in associated costs, including risk management, employee onboarding, security processes, monitoring, and more.
And with increased efficiency, automated data processing also offers us a greatly enhanced degree of scalability within affected processes. Essentially, the relative unit cost of actioning a process is lower, so we can achieve more with fewer resources.

(WTWCO)
Challenges
However, none of this is to say that data automation is a straightforward undertaking. Indeed, we must also be cognizant of a whole raft of costs, risks, and other considerations that may shift our value calculations.
The first thing to note is that - although it will almost certainly provide value down the line - configuring data automation across your company isn’t free. So, we have to contend with the costs of automation platforms, hosting tools, and the labor hours to get them up and running.
… which leads us to another critical point.
Undertaking data automation successfully requires us to have the appropriate internal skills and expertise. Moreover, even where we have the required talent, we also need these colleagues to have the capacity to transform our DataOps.
This is a big ask in the context of tight economic conditions, a global shortage of development talent, and unprecedented demand for digitalization. We’ll check out some of the ways that new technologies are alleviating the burden here a little later.
Finally, data automation isn’t exempt from the risks and challenges that we’d need to deal with within any other major transformation project. So, we might encounter scope creep, project dependencies, sunk costs, or a whole raft of other challenges.
None of these are necessarily inevitable or insurmountable, but we must nonetheless remain conscious of their potential to undercut the financial benefits of data automation.
How to create a data automation strategy: 6 steps
So far, we’ve extensively covered the theory behind data automation. Now, we can move on to fleshing out our understanding and thinking about how you can apply this to your own real-world pain points.
1. Identify your problem
First of all, we need to state the problem that we want to solve. Even if this seems self-evident to you or you have a specific pain point in mind already, it’s worth reflecting on the concrete impact we want to have through implementing automated data processing.
We can start by determining the scope of our project. Are we only going to deal with a specific process or are we attacking our entire data operations?

(Zapier)
We’ll also need to consider the exact issue we’re seeking to address, along with how we’ll operationalize this. Cast your mind back to the benefits of data automation that we thought about earlier.
The key thing here, as ever, is to have clearly operationalized goals. The idea is that we should have a repeatable way to measure whatever aspect of our data ops that we’re trying to improve - along with a defined target that we’re trying to reach in a defined time frame.
So, if our overarching objective is improving efficiency within a given process, we might operationalize this as a 50% reduction in the associated labor costs over a six-month period.
2. Inventory data assets
Once we know what we want to achieve with data automation, we must turn our attention to inventorying all of the relevant data assets. Pay attention here, because this is a widely overlooked step.
Essentially, we need to document all of the data we’re going to leverage with our automations. For instance, the specific entities we need, the attributes that are stored against each of these, and the sources we’ll draw them from.
The issue where many automated data processing projects fall down here is to do with process dependencies.
Basically, a large proportion of initiatives are sunk by spiraling costs because companies realize too late that to get value out of automating one area of their data ops, they’ll need to do the same with interrelated processes.
Therefore, the more effectively you inventory your required data assets, the more accurately you’ll be able to ascertain the scope of your project. This allows us to make better-informed decisions in subsequent parts of our strategy, as well as helping to keep the project on track.
You might also like our guide to CAP vs ACID.
3. Outline and prioritize data processes
Next, we’ll outline the specific data processes we’re going to automate - first, in more abstract terms. This looks a lot like gathering functional requirements for any other kind of transformation project.
Effectively, we’re outlining the business logic that we ultimately plan to automate. For example, if X event occurs, we need Y to happen.
In other words, we want to define the specific transformations and processes that will be applied to our data assets and the conditions that govern when and why these happen.
Another important aspect of this is prioritization. What do we mean here? The thing is - we’ll often come up against situations where we’re constrained by factors besides just the technical side of things.
For instance, we may find that we need to focus our efforts because of limited resources or development capacity. Therefore, we’d need to decide how we want to prioritize. There are a few different but equally valid ways of going about this.
One option is starting with the easy wins. That is, we can focus our attention on the processes and operations that will take the least effort to automate. The idea here is that we’ll see the benefits more quickly and therefore free up resources for more involved tasks.
On the flip side, we might instead opt to start with the operations that we’ll reap the biggest rewards from automating - in an effort to have the biggest possible impact as quickly as possible.
4. Implementation planning
At this point, we can figure out how we’re going to automate the processes that we’ve identified. Obviously, it gets tough to generalize here, since you could be dealing with any type of data or process.
So what decisions will you need to make here?
For a start, you’ll need to determine the appropriate class of automation solution, based on the process in question, your capabilities, resources, and goals.
We might need to balance the relative costs and benefits of leveraging RPA, custom app development, data pipelines, machine learning, or a whole range of other strategies - or even several of these in combination.
Another thing to consider is the fact that we’ll also be constrained by indirect costs. For example, we’d need to account for the costs of licensing specific tools, maintaining solutions, onboarding staff, and the opportunity costs associated with the time to automate work.
Plus, if we need to boost technical capabilities to implement a particular solution, we’ll need to factor this in too - both in terms of time and the financial burden. For instance, additional network infrastructure.
5. Execution
The execution phase comprises all of your efforts to actually implement your chosen solution. Again, there are a huge number of potential permutations of how this could play out. So, we’re best focusing on the most common issues you’ll encounter.
Obviously, a massive piece of the puzzle will be developing or configuring your automations themselves - as well as other technical work to support this. For example, testing, QA, monitoring, maintenance, and deployment.
However, we’ll also need to pay attention to less technical aspects of the rollout of our automated data processing solutions.
Training is a huge part of this. See, one of the core planks of data automation is empowering your team to be more productive and take better-informed decisions.
Almost invariably, we’ll require some element of additional training for how colleagues will interact with data going forward.
For instance, we might need to trigger automated data processing with user actions - in which case, our team needs to know how and when to do so. Or, they might only need to train colleagues on how to interact with this data to get the insights they need.
As such, we’ll naturally need to plan around this - taking into consideration both our team’s day-to-day needs and their existing level of competence.
You might also like our guide to relational vs non-relational databases.
6. Follow-up, review, and optimization
Unfortunately, the work doesn’t stop once our data automation solutions are in-situ. Instead, we’ll need to account for a whole raft of follow-on activities across the lifecycle of our solution.
In the first instance, a big part of our focus will be on how effectively we’ve implemented it from an entirely functional standpoint. In other words, does what we’ve put in place actually meet the requirements we outlined earlier?
We can then start to explore how we could improve on our initial implementation.
So, say everything was working as intended. We might still determine that we’d still benefit from further improvement and optimization. Of course, this could come in a whole array of different forms.
For instance, by adding further automations around related workflows, boosting capacity, or altering the existing sequence of steps within our existing data automation approach.
How to automate data processing
So far, we’ve covered a lot of different scenarios where we’d had to generalize because of the wide possibilities under the umbrella of data automation. To solidify our understanding, it’s worth thinking through how we would attack some specific use cases.
Say you had a process that involved transferring order information from your CRM to your accounting software. Very broadly speaking, our automation solution would need to do three things:
- Connect to each platform in order to query their stored data.
- Perform any required transformation to make the data compatible across the platforms.
- Get the relevant CRM data and add it to the accounting software when a defined condition is met - for instance, a payment completing.
This is a massively simplified account of how this would work in the real world, of course.
Let’s think about each piece of the puzzle in turn. Connecting to the relevant data is the easy part since we can just rely on APIs or webhooks, provided the platforms in question support this.
For the other two steps, we’d likely leverage some intermediary platform to perform the required transformations and trigger our automation rule - likely either a dedicated automation tool or a low-code platform.
Take a look at our guide to WebHooks vs APIs.
Data automation tools
In truth, there’s a broad spectrum of tools we might leverage to automate data processes varying hugely in the nature and scope of their functionalities.
So, we might equally leverage highly specific tools that aim to solve a very granular use case - or we might rely on a single broader platform for a whole raft of applications.
Alternatively, we might get pretty far by only leveraging automation features within the tools we already use for managing relevant processes.
For a roundup of some of the most ubiquitous options across each of these categories, check out our ultimate guide to the top data management software solutions.

Introducing Budibase
Budibase is revolutionizing the way countless businesses manage their internal data. Our open-source, low-code platform is the fast, intuitive way to build everything from dashboards and CRUD apps to solutions for a wide range of data automation problems.
Let’s check out what makes Budibase such a game-changer.
Our open-source, low-code platform
Budibase is the clear choice for IT teams that need to output solutions quickly, without compromising on quality. With extensive data support, intuitive design tools, and fully auto-generated CRUD screens, it’s never been easy to ship custom web apps.
Check out our features overview to learn more.
External data support
We’re proud to lead the pack for external data support. Budibase offers dedicated connectors for SQL, Postgres, Airtable, Google Sheets, Mongo, Couch, Oracle, S3, Arango, REST API, and more.
We also have our own built-in database, so it’s never been easier to create custom applications on the fly.
Self-hosting and cloud deployment
Security-first organizations love Budibase for the ability to host their automation solutions on their own infrastructure. Self-host with Docker, Digital Ocean, Kubernetes, and more.
Or, use Budibase Cloud and let us handle everything. Check out our pricing page to learn more about both options.
Configurable RBAC
Budibase offers configurable role-based access control, to perfectly balance security and accessibility.
Assign roles to users and tightly control permissions at the level of data source, queries, screens, or individual components.
Dedicated automation builder
Our automation builder is the easy way to replicate business logic with minimal custom code. Nest, combine, and loop our built-in actions to create sophisticated automation rules.
We also offer support for third-party integrations as automation triggers and actions using WebHooks, Zapier, and REST.
Custom plug-ins
Budibase leads the pack for extensibility. Build your own components and data sources and ship them across your Budibase tools using our dedicated CLI tools.
Check out our plug-ins page to learn more.
50+ free app templates
We have a lot of confidence in what our platform can do - but why should you take our word for it?
We’ve created over 50 free, customizable app templates to help get you started.
Sign up for Budibase today for free to start building custom applications the fast, easy way.