
Getting your data model right is the first step in any successful development or transformation project. Today, we’re exploring everything you need to know about relational vs non-relational databases.
This has become a tougher decision in the past decade or so. Until relatively recently, the relational model was pretty much the dominant way of storing data.
Today, it’s still by far the most ubiquitous option - but other approaches have also entered the mainstream.
The rise of big data, AI, IoT, and a whole range of related disciplines have helped spurn the growth in popularity of non-relational databases. Today, non-relational data models are served by a growing number of new platforms, vendors, and tools.
This presents us with a challenging landscape to navigate. See, it’s vital that you understand how to select the right model for your specific needs.
That’s exactly what we’re going to cover today.
Specifically, we’re going to check out the key distinctions between relational vs non-relational databases - in terms of definition, applications, use cases, key personas, and their respective benefits and challenges.
Then, we’ll wrap up with some of the key considerations that you’ll want to keep in mind to make a decision of your own.
Let’s jump in.
Relational vs non-relational databases
We’ll start with the definitions of each, along with a little bit of background to explain their core characteristics.
What is a relational database?
As the name suggests, relational databases are built around what’s known as the relational model. This means that data is stored in in tables that are made up of strictly defined rows and columns.
Each row is an entry in the database while the columns are the attributes that can be stored against them.
We can define constraints on each attribute - stipulating that it must be of a particular type or format - or that it must follow some other rule, like being unique.
The idea here is that data is standardized across our table.
The relational model also allows us to define relationships between multiple tables. This requires us to define what’s known as the table’s primary and foreign keys.
This works as follows:
- A table’s primary key serves as a unique identifier for each individual row.
- The foreign key is an attribute that refers to the primary key of a row in another table.
- Each table must have one primary key, which is unique for each row.
- A table can have multiple foreign keys for different relationships.
For example, we might have two tables - one for our employees and one for their company cars. So, the employees table has all of their personal and professional details. The cars table stores things like the make, model, service requirements, license plate, etc.
Storing these on separate, related tables means that we can quickly update an individual’s car without altering their other information. Or, we could quickly query every employee who drives a Ford, if we needed to initiate a recall, for instance.
It’s also important to note that there are different kinds of relationships. So, in our example, we’d likely use a one-to-one relationship, since each employee only needs one company car.
We can also use many-to-one relationships. For instance, if we had one table for all of our employees and another for each department within our company - each employee would belong to one department, but each department would have many employees.
Then there are many-to-many relationships. As in, each employee could be related to multiple projects.
This is a very high-level view of how relational databases work. We’ll check out some more concrete details a little bit later.
Examples
For now though, let’s check out some examples of relational databases. The relational model is synonymous with one thing - SQL.
That is, Structured Query Language.
As the name suggests, this is a language rather than a database management system. This has been the standard way to interact with relational data for almost fifty years now.

Today, there are a whole array of different SQL-based databases out there, so it’s worth briefly going through some of the most common examples.
SQL Server AKA MSSQL is Microsoft’s offering - and kind of the industry standard. As such, it benefits from a familiar, intuitive interface, that’s well-understood by most data professionals.
The downside is that it’s relatively expensive compared to some of the other options out there - especially at scale.
MySQL is an open-source alternative, with similar functionality, and a huge wealth of documentation. Since it’s open-source, it’s also a little bit easier to extend than SQL Server. However, it also has a reputation for being a bit less scalable.
Then we have PostgreSQL, which takes a slightly different approach. Postgres is also open-source but it uses what’s known as the object-relational model.
So, we can still use SQL queries to interact with data, but we have some of the functionality we’d get with an object-orientated database, like classes, inheritance, objects, and a huge degree of extensibility - including user-defined data types.
Other popular relational DBMSs include Oracle, Snowflake, Amazon Aurora, and IBM DB2.
You might also like our guide to CAP vs ACID.
What is a non-relational database?
In truth, most developers and even technical non-developers are pretty comfortable with relational databases - since they’re just so ubiquitous, it’s unlikely that any IT professional could escape them.
On the flip side, it’s much harder to take for granted that you might have encountered non-relational databases - or at least, that you’d have worked with them extensively. So, we won’t assume any prior knowledge.
At a very basic level, a non-relational database is anything that stands outside of the relational model we’ve just outlined. Most often, this isn’t stored in tables at all, so it’s often also referred to as unstructured data.
Instead, non-relational databases might use whatever type of storage that’s suitable for the task at hand.
Confusingly, you’ll often see the term NoSQL used, although many non-relational databases do support SQL-like queries. As such, the more accurate but less catchy term Not Only SQL is also used sometimes.
Non-relational databases are used to store information that doesn’t fit neatly into defined structures - like emails, videos, business documents, or any really big data set.
4 types of non-relational databases
So, that doesn’t give us a huge amount of information to go on, since it’s a very broad definition. Helpfully though, there are really only a few common types of non-relational databases.
Actually, we can point to four categories that are used in practice.
These are:
- Document-orientated databases - for storing documents and document-orientated information. Keys are paired with a complex data structure (a document).
- Key/Value stores - A simple data structure where each key is paired with one value - a little bit like a dictionary.
- Wide-Column stores - A table-like structure, where the data types, formats, and even attributes stored can vary between different rows.
- Graph stores - A structure based around interrelated nodes of data. Data is stored as nodes, properties, and edges.
We’ll flesh each of these out a little bit later when we come to look at some real-life use cases.
What’s important to realize for now is that non-relational databases aren’t just one singular way of storing data.
Rather, there’s a bit of a spectrum to get to grips with.
Examples
So, let’s look at an example of each of our four categories of non-relational databases.
MongoDB is probably the most ubiquitous non-relational database engine on the market. It’s certainly the most popular document-orientated database. It is based around JSON-like documents that can be stored and run across multiple servers.
MongoDB is also popular because it offers advanced functionality - like auto-sharding, making it highly suited to projects that require large data sets.
One of the most well-known key/value stores is Redis (Remote Dictionary Server). Redis is also open-source, and supports a wide range of data types, making it suitable for a huge variety of projects.
One downside, however, is that you’ll need some Lua coding skills in order to use it.
Amazon’s DynamoDB is perhaps the best-known wide-column store, while the most widely used graph database is probably Neo4j.
Join 300,000 teams running operations on Budibase
Get started for freeRelational vs non-relational databases: pros and cons
So, what have so many non-relational databases gained ground in the past decade? While some people are quite zealous about specific tools, the more boring reality is that different approaches have their own pros and cons.
Let’s take a look at each in turn.
Relational databases
Remember, relational databases are - for many people - the way we interact with data. That is, they’re essentially the norm.
Pros
First, let’s think about why the relational model is so ubiquitous. Actually, one benefit is its ubiquity itself. That is, every developer - and even most non-developers - can work pretty comfortably with relational databases.
Therefore, colleagues can easily start working with unfamiliar data sets, with minimal delays. We can also expect a huge degree of interoperability between platforms that draw on relational data.
Also, SQL syntax is very close to plain English, so learning it is comparatively easy, even for non-technical colleagues.
SQL databases also afford us a huge degree of control over how we store and manage our data. We’re able to enforce very strict structures for our data set, including highly granular constraints on individual attributes.
In turn, this allows us to ensure a large amount of consistency and accuracy within our data management workflows.
The relational model also brings along ACID compliance, which helps us to maintain the security, continuity, and integrity of our data, without compromising on the speed of our querying - making them perfect for transactional use cases.
Cons
However, the relational model is not without its limitations. The big thing is that data doesn’t always fit into a neat, tightly defined structure. These kinds of situations can make SQL difficult to leverage.
For instance, if you want to store different attributes for individual entries, things will get messy.
On top of this, the way we generally work with relational data can constrain us and make it difficult to respond to changing requirements - since we generally define a schema up front, which then becomes sticky and awkward to modify.
This can also make relational databases a less attractive option for rapid app development projects, or other situations where we simply want to ship a working tool quickly and then modify our data layer later.
We might also consider an alternative option when scalability is a major concern - or within big data projects, where we need to deal with large volumes of unstructured data.
Non-relational databases
Thinking about the pros and cons of non-relational databases is a little bit more challenging, knowing as we do that this actually comprises a few distinct categories of data storage.
So, it’s useful to think specifically in terms of what benefits non-relational models can offer vs relational databases.
Pros
A number of benefits of non-relational data stem from the flexibility that it offers us within development or transformation projects. So, we are able to store and manage large volumes of data, without the need for a defined structure.
In turn, this provides us with a greater degree of flexibility and scalability. If we need to add more data that differs from what we already have in terms of form or content, it isn’t an issue.
Many non-relational databases also offer schema on-read functionality, meaning that a schema is enforced when the data is queried, rather than when it is created. So, you can adapt the structure of the data to the needs of individual users or tasks.
This also positions non-relational databases as more suitable for certain classes of information - including documents, or other unstructured media files.
Non-relational models are also a vital component of the big data revolution.
When it comes to processing truly enormous volumes of data, we simply need an unstructured approach. Non-relational databases are also much more suited to storing and manipulating data in real-time.
Cons
Of course, non-relational databases also come along with their own challenges and shortcomings.
Usability is a huge factor here. The reality is that, compared to SQL, it’s relatively unlikely that your team will already know how to use a given NoSQL tool - unless they’ve had cause to do so before.
For most development projects, this might cause a bit of a delay, but shouldn’t be a total deal breaker, since developers learn to use new technologies all the time. However, it might be more challenging for less technical colleagues to get up to speed with NoSQL tools.
This can present real barriers if users don’t have the technical skills they need to utilize non-relational tools. Of course, there are workarounds out there. We’ll check out how Budibase handles non-relational data sources a little later.
Finally, you’re more likely to encounter compatibility issues when your data uses less common standards. With SQL, most tools are going to offer connectivity.
If our data lives in a particular non-relational database, it’s going to be more of a challenge to find a suitable COTS platform that supports it for any given use case.
User personas
To flesh out our understanding of the respective cases for using relational vs non-relational databases, it’s worth getting to know their key users a little bit better. So, let’s think about who typically uses each.
We’ll take relational databases first - since it’s a much more straightforward answer.
Everybody.
We’re being flippant here, but it actually points to an important point. It’s hard to imagine a more established standard for anything than SQL. It’s used by developers and data professionals around the world.
But, it’s also used by countless marketers, finance professionals, salespeople, executives, operations specialists, administrators, and more. In essentially any discipline, some knowledge of SQL will put you at a huge career advantage.
On the other hand, non-relational databases aren’t quite niche anymore, but they’re typically used by a much narrower field of personas. Data professionals make up a big segment of this - whether these are data scientists, DevOps pros, or back-end engineers.
This is not to say that NoSQL tools are used exclusively by these kinds of technical colleagues. Rather, these are the sorts of personas that are most likely to be at the nexus of two things:
- Encountering use cases where non-relational data is imperative.
- Having the technical skills to implement solutions.
We might equally find colleagues in other roles who meet these criteria.
Use cases
Therefore, it’s important to think more deeply about some of the key use cases for relational vs non-relational databases.
Of course, we couldn’t possibly go through every possible application of each.
Instead, we can check out some illustrative examples of each.
Relational databases
SQL is so widely used that it’s challenging to even begin to select exemplar use cases.
Relational databases are used in the vast, vast majority of business applications, inventories, internal processes, dashboards, and development projects.
The most basic example of this is what’s known as a CRUD application. This is a simple user interface that’s used for all sorts of administrative workflows, allowing colleagues to create, read, update, or delete database entries.
For example, say we had a database that stores something simple, like our employee’s contact details. Rather than manually querying this every time we want to look up or change a phone number, we might build an app to manage this - a CRUD app.
This is incredibly easy in SQL since there are so many tools out there that will allow us to build a suitable interface in as little as a few seconds. We’ll touch on how to do this in Budibase a bit later.
This is about the simplest example of an application we could build with SQL.
Where it gets interesting is when we need to represent and manage multiple, interrelated entities. SQL really comes to the fore in such scenarios.
For instance, we could build on the above example to build a more complex tool that allows users to manage a more complex data set. In terms of querying, SQL offers a huge degree of power and flexibility, to the extent that the possibilities are nearly limitless.
We’ll check out how querying works in SQL in the next section.
Non-relational databases
Non-relational databases have a slightly different set of use cases - although there are plenty of situations where either model might be a viable option. What we’re really interested in is the situations where only a non-relational database will do.
We’ve alluded to a lot of the key use cases already - at least in passing.
One of the most important is big data applications. So, things like data warehousing, data lakes, and other centralization or cloud migration projects.

(DNB)
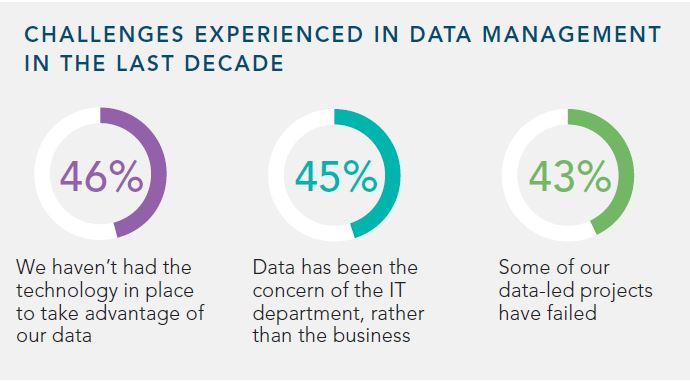{kind=link}
Essentially, when we have enormous stores of data, we’re constrained by the fact that all of this is unlikely to fit neatly into a strict schema - so we need solutions that can handle unstructured data.
Similarly, document management is an important use case for non-relational databases. Digital media, like files, images, text documents, emails, or other assets need more complex data structures if we want to do anything but the most basic of operations to them.
Non-relational databases are also useful in situations where we need to access data in real-time. For example, if we needed second-by-second reporting on some mission-critical metric, we’d likely require some kind of non-relational database.
Interacting with data in relational vs non-relational databases
We’ve covered an awful lot of material so far. Before we wrap up, it’s worth thinking through how we interact with data in relational vs non-relational databases at a practical level.
So, let’s think about how querying works in different kinds of databases.
We know already that SQL is by far the most common way of interacting with data - with the possible exception of spreadsheets.

(McKinsey)
But why?
We said earlier that syntactically, SQL is very close to English - making the barriers to learning it pretty low. It’s also relatively easy to understand what’s going on in an existing SQL statement.
The most common SQL commands include:
- SELECT - extracts data.
- UPDATE - updates data.
- DELETE - deletes data.
- INSERT INTO - inserts new data.
- CREATE DATABASE - creates a new database.
- ALTER DATABASE - modifies a database.
- CREATE TABLE - creates a new table.
We can also add conditions to any of these statements using the WHERE command. So to select all the entries in a table called products that have a cost attribute above 10, we’d use something like:
SELECT * FROM products
WHERE cost > 10;
Things aren’t so uniform in non-relational databases, since there isn’t quite an established standard. Some vendors will have their own requirements. For instance, we mentioned earlier that Redis will require some knowledge of Lua.
Other tools will allow you to query data using commands that greatly resemble SQL - only with some degree of change as is required to suit the structure of the data at hand.
So, the amount of upskilling that’s required to get up and running with NoSQL databases can vary greatly between different vendors. Therefore, it’s vital to do your due diligence before committing to a particular type of solution.
You might also like our in-depth guide to data automation.

Turn data into action with Budibase
At Budibase, our mission is to help teams turn data into action. Our open-source, low-code platform is the fast, easy way for developers and non-technical colleagues alike to build professional web apps.
Let’s take a look at what makes Budibase tick.
Our open-source, low-code platform
Budibase is built to make common development tasks a breeze. With intuitive design tools, autogenerated CRUD screens, and incredible extensibility, there’s never been a better way to build custom solutions.
Check out our features overview to learn more.
Extensive data connectivity
Budibase leads the pack for external database support. We offer dedicated data connectors for SQL, Postgres, Mongo, Couch, S3, Oracle, REST, Google Sheets, Arango, Airtable, and more.
We also have our own built-in database with full support for CSV uploads and simple relationships. Take a look at our ultimate guide to data management software solutions.
Optional self-hosting
Our users love Budibase for the ability to self-host their tools. Deploy Budibase to your own infrastructure using Kubrenetes, Docker, Docker Compose, Digital Ocean, and more.
We also offer proprietary cloud-based deployments through Budibase Cloud. Check out our pricing page to learn more about both options.
Intuitive automation
Budibase makes it easy to automate all sorts of workflows, with minimal custom code. Use our intuitive editor to combine, nest, and configure a range of built-in triggers and actions.
Use Zapier, webhooks, and REST to use external events as automation triggers or actions.
Configurable RBAC
Create the perfect access rules to maximize security and usability alike with Budibase’s built-in role-based access control.
Add users to a predefined role and set permissions at the level of data sources, queries, automations, screens, or even individual components.
Custom plug-ins
No other low-code platform comes close to Budibase for extensibility. Build your own components and data sources to ship across your low-code apps using our dedicated CLI tools.
Check out our plug-ins page to learn more.
50+ free app templates
We’re so confident in what our platform can do, that we decided it only makes sense to show you. Check out our collection of over 50 free, deployment-ready, and fully customizable application templates.
Sign up to Budibase today to start turning data into action.